
GPT
发表时间:2025年12月16日浏览量:
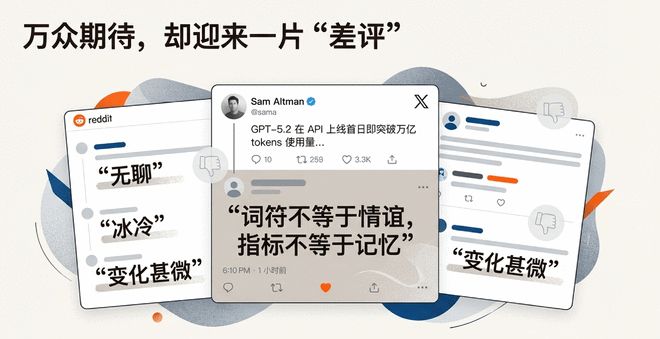 作者 |创建者:陈陈 |网易科技很强大,也很无聊。奥特曼在 Twitter 上庆祝 GPT-5.2“第一天消耗一万亿代币”,但过去三天,评论区已被撤回。用户并不买账。面对GPT-5.2,最直观的感受不是“发疯”,而是“敷衍”。 “言语不等于友谊,符号不等于记忆。”网友的这句赞扬,准确地表达了公众对“消防升级”的集体冷漠。 (AI生成的图片)但是真相真的有那么难吗?经过三天多方的深入测试,以及克劳德 4.5 和 Gemini 3 的并列比较,我们得出了一个反直觉的结论:它可能确实“烦人”,但这是为了更强而付出的代价。 1、全网嘲笑“无聊”?用户实际上可能会误解,这次仓促推出并不是因为精心策划,而是出于某种目的。危机的nse。消息人士透露,OpenAI宣布进入“红色警报”(Code Red)正是为了应对谷歌Gemini 3等竞争对手日益加大的压力,不得不加快发布速度。不过,这次“救火”升级并没有像 GPT-4 发布时那样在社交媒体上引发病毒式疯狂传播。 Reddit 和 X 上充斥着“无聊”、“冷漠”、“变化不大”等负面评论。科技博主@melvynxdev甚至声称GPT 5.2的发布是一场灾难。与 OpenAI 声称的“迄今为止最适合专业知识工作的系列模型”相比,公众对 GPT 5.2 的整体“冷漠”形成了鲜明的对比,甚至 OpenAI CEO Sam Altman 表示“GPT-5.2 在 API 上线第一天就突破了万亿使用代币,增长势头很快”,不少用户评论道:“文字不等于友谊,指标不等于内存”、“万亿代币被使用”。第一天消费,并且那么,GPT 5.2到底是“史上最强大的工具”,还是竞争对手强行推出的“无用”升级?我们深入挖掘了最新的专业评论和技术评论,发现网络批评可能完全误解了5.2的设计目标。 2.明白“烦人”的真相——结果至上的产品理念是高级产品经理KARO传授的,如果GPT 5.2被认为是展示和追求“掌声”,可能会令人失望;但如果将 GPT 5.2 视为一种追求长期稳定性并需要实际部署的工具,它超越了 OpenAI 在 GPT 5.2 中做出的一个重大产品决策:牺牲一些表达自由和创造性模型范围,以换取可预测和可靠的行为。这种不稳定是错误的。在处理具有实际下游成本的任务时,例如政策制定、规范性文件或进行认真的研究简报,这种投入是完全不可接受的。 (AI生成的图片) GPT 5.2的设计目标是保持可靠性并降低故障频率。为了实现这一目标,主要在以下三个维度进行优化: · 更严格的指令遵循:模型能够更忠实地执行用户的指令。 · 减少长时间对话中的脱轨:即使对话很长,模型也能保持话题不偏离正轨。 · 在多步骤任务中保持约束:即使任务进行了几十个步骤,它也能记住用户在步骤 1 中设置的规则。(AI 生成的图像)在一次密集的专业测试中,研究人员加载了 8,100 行原始研究数据,并设置了绝对的“绊线”规则:如果用户应该只将输出“黄色”。 GPT 5.1 在大约 47 分钟后终于打破了规则,而 GPT 5.2 rem经过 62 分钟的持续语义归纳和上下文压力后,测试人员一直处于顺从状态,直到测试人员主动停止。这证明 GPT 5.2 非常有能力在复杂的非线性对话中遵循规则。平衡动态推理和成本效率 GPT 5.2 采用“动态调整推理深度”的方法。简单提示用户先走“快捷路径”;当不确定性超过一定限度时,就会启动更慢、更深入的推理。此方法提供了最快且最便宜的回答问题的方法。虽然 GPT 5.2 的单位代币成本比 5.1 高出 1.4 倍,每百万代币的输入成本为 1.75 美元,每百万代币的输出成本为 14 美元,但得益于学习蒸馏、缓存常用文本效率片段、缓存常用效率片段和效率片段等前沿模型的最佳实践,任务成本降低了。例如GPT-5.2 Pro约390吨与去年的预览版本相比,ARC-AGI-1 任务的表现更好。减少幻觉:宁愿说“我不知道” GPT 5.2 施加了更高的惩罚机制,以防止在更大范围内引用、谎报工具的使用情况或制造未知事实。这意味着新模型更有可能承认“我不知道”,或者要求用户提供更多来源或搜索权限。这种看似“冷酷”或“保守”的行为无疑是依赖其准确性的专业用户的信任基础。 (图片由AI生成) 3.专业领域的终极对决:数据分析、PPT和编码 YouTube名人博主Eliot Prince对三种主要模型进行了深入的对比评估。他把GPT 5.2、Claude Opus 4.5和Google Gemini这三个主要模型用来测试复杂的专业任务,包括SEO策略的制定(搜索引擎优化)、PPT开发和编码。 1. SEO策略和数据分析是:Claude的“One Hit Win”测试人员上传了数千行关键词数据,并要求模型制定完整的SEO主题权威策略和主题图。 · Claude Opus 4.5:表现最佳、速度最快、“一击制胜者”。它使用 Claude Skills 自动应用品牌设置,创建带有品牌徽标、mga 品牌颜色(紫色和柠檬绿)的专业表格,包括内容分段、搜索意图、推荐页面类型和优先级信息。 · ChatGPT 5.2:思考这个问题大约 15 分钟。最初的输出相当混乱,需要第二次测试和模板(另一个电子表格)来输出按内容主题分类的可用关键字簇,其中可以包括搜索量和关键字难度等专业数据。这表明 GPT 5.2 是完全可启动的,但不像 Opus 最初那样自主。 · Google Gemini:效率低且难以利用。它只是输出一个“弱”小文件。即使测试人员问了很多问题mes,它只提供CSV文本信息或Python代码,需要用户手动复制粘贴并进行文本列处理,效率低下,并且有很多错误rap经验。 (图像由AI生成,插图不代表实际效果) 总结:在需要品牌推广和一站式交付复杂数据分析结果的任务中,Claude Opus 4.5是毫无疑问的赢家。 2. PPT生成:GPT 5.2“史诗级”图表。为了满足客户对视觉策略的需求,测试人员需要三个模型分别开发PPT。 · ChatGPT 5.2:我花了14分钟才弄清楚这一点,但结果可以用“史诗般”来形容。虽然设计相当令人愉悦,但它成功生成了动态动画图表,可以快速显示流量机会并提供 30 至 45 天内可交付成果的详细路线图。 · Claude Opus 4.5:很快就完成了。 PPT成功应用了审稿人的品牌颜色(森林绿和石灰绿)n) 而且布局精美。但其后续步骤的细节并不像GPT 5.2那么详细。 · Google Gemini:同样性能不佳,更喜欢输出Python脚本或纯文本。最终生成的PPT也有很多文字和很少的图表,看起来“几乎是AI生成的”,并且很难导出到Google Slides进行编辑。 (图片由AI生成,插图不代表实际效果) 总结:三个主模型在制作PPT上有些卡壳。 GPT 5.2 在图表深度和功能上稍好一些; Opus 4.5 再次以其标志性的交付能力脱颖而出。 3.编码能力:功能、速度和发布三个模型的测试人员被要求扮演高级前端工程师的角色,根据网站截图重建一个交互式的、专业设计的网页。 · ChatGPT 5.2:比两者都多花费 5 到 10 分钟。但最终功能还是稍微好一些。它不仅实现了测试人员所需的所有共享、定价和其他按钮,还构建完整的订单表格和预约表格,增加更多深度和功能,考虑更多细节。 · Claude Opus 4.5:很快完成。生成的页面支持发布生成“神器”和复制链接,使其成为实时网页或登陆页面,非常实用。设计也很棒,包括漂亮的悬停效果和货币切换功能。 · Google Gemini:第一个完成,但缺乏全屏预览和发布功能,需要调用外部HTML编辑器才能查看。交互性很差,页面区域的按钮只是占位符,无法执行任何操作。 (图片由AI生成,插图不代表实际效果) 总结:GPT 5.2虽然耗时最长,但由于其生成完整表格的深度和功能性,稍稍领先。 4.秘密战斗b创造力、视角和背景之间。在生成电子邮件主题行和打开挂钩的日常任务中,测试结果表明所有模型的表现大致相同,没有一个模型表现出巨大的创意优势。专业评论指出,GPT 5.2牺牲了一些创造力的空间来换取可靠性。因此,建议用户根据需求切换模型:对于“创意头脑风暴、绘图或情绪基调”等任务,maai 选择 GPT 5.1;对于“编辑、精简、编写事实、编写细节或编码”等任务,您应该选择 GPT 5.2。需要指出的是,虽然GPT 5.1的书写能力并不令人印象深刻,但它在分析损益报告等长期任务上表现良好,可以连续运行两个小时并提供准确而整洁的摘要。在形象生成方面,双子座出乎意料地获胜。测试人员的任务涉及视觉、分析和创意方面的融合:建立一个内部基于他上传的简历,以星球大战为主题的有趣职业信息图。 · ChatGPT 5.2:性能非常差。它在遵循内容政策方面存在问题,并且生成了低质量的图像,甚至无法正确拼写名称或文本。 · Google Gemsini(纳米香蕉):彻底碾压并获胜。它可以有效地捕获信息,生成清晰、拼写正确且设计精美的图形,甚至可以为命令添加“全息效果”。 Claude Opus 4.5:没有内置图像生成,但它试图通过编写代码来解决问题。最终成功创建了一个可发布、可交互的网络。 《星球大战编年史》中的页面信息图表映射种族,在编码方面表现出强大的灵活性。 (图片由AI生成,插图不代表实际效果)最终,双子座在纳米香蕉的支持下取得了明显的胜利。当然,OpenAI本身也强调了GPT-5.2在图推理和软件接口方面的错误率ce理解力下降了一半,说明虽然视觉能力有所提高,但图像生成仍然是一个短板。另外,在用户交互分析方面,Claude Opus 4.5的上下文窗口处理能力更加出色。随着对话的继续,Opus 4.5 开始压缩旧的对话内容,使其可用时间更长,从而使用户免去必须重新开始新聊天的烦恼。此外,Opus 4.5培训还包括一份名为“灵魂文档”的内部文件,该文件明确了Anthropic的使命——开发安全、有用且易于理解的AI,并警惕主动的言语攻击,解释了为什么Opus在安全性和合规性方面表现良好。 5、总结:模型定位与用户选择 GPT 5.2的发布,标志着AI巨头之间的竞争已经从追求“最高基准分数”转向追求“实用的产品策略”信任、安全、速度和成本”。模型进步变得更加专业。(AI生成的图片) · GPT 5.2可以说是可靠的主力,具有良好的屏障保持性和更严格的指令合规性。适合内容编辑、规范起草、审阅长文和深度函数式编程等任务。 · Claude Opus 4.5是品牌和数据的大师。它速度快,拥有高度优化的上下文窗口,一击必胜。更适合复杂数据分析、创意草稿、需要品牌输出的任务,Google Gemini 在图像和信息图开发、PDF 数据捕获等任务上更胜一筹,但专业任务的交付质量较低。(AI 生成的图像)那么,答案很简单:如果你需要一个严格的“执行者”,请毫不犹豫地拥抱它;如果你需要一个聪明的“创造者”,请回去看看。对于克劳德. OpenAI 并没有输,只是改变了轨道。作为用户,我们是时候摆脱“只是观看”的心态,开始思考如何充分利用这些专业的“数字员工”了。
作者 |创建者:陈陈 |网易科技很强大,也很无聊。奥特曼在 Twitter 上庆祝 GPT-5.2“第一天消耗一万亿代币”,但过去三天,评论区已被撤回。用户并不买账。面对GPT-5.2,最直观的感受不是“发疯”,而是“敷衍”。 “言语不等于友谊,符号不等于记忆。”网友的这句赞扬,准确地表达了公众对“消防升级”的集体冷漠。 (AI生成的图片)但是真相真的有那么难吗?经过三天多方的深入测试,以及克劳德 4.5 和 Gemini 3 的并列比较,我们得出了一个反直觉的结论:它可能确实“烦人”,但这是为了更强而付出的代价。 1、全网嘲笑“无聊”?用户实际上可能会误解,这次仓促推出并不是因为精心策划,而是出于某种目的。危机的nse。消息人士透露,OpenAI宣布进入“红色警报”(Code Red)正是为了应对谷歌Gemini 3等竞争对手日益加大的压力,不得不加快发布速度。不过,这次“救火”升级并没有像 GPT-4 发布时那样在社交媒体上引发病毒式疯狂传播。 Reddit 和 X 上充斥着“无聊”、“冷漠”、“变化不大”等负面评论。科技博主@melvynxdev甚至声称GPT 5.2的发布是一场灾难。与 OpenAI 声称的“迄今为止最适合专业知识工作的系列模型”相比,公众对 GPT 5.2 的整体“冷漠”形成了鲜明的对比,甚至 OpenAI CEO Sam Altman 表示“GPT-5.2 在 API 上线第一天就突破了万亿使用代币,增长势头很快”,不少用户评论道:“文字不等于友谊,指标不等于内存”、“万亿代币被使用”。第一天消费,并且那么,GPT 5.2到底是“史上最强大的工具”,还是竞争对手强行推出的“无用”升级?我们深入挖掘了最新的专业评论和技术评论,发现网络批评可能完全误解了5.2的设计目标。 2.明白“烦人”的真相——结果至上的产品理念是高级产品经理KARO传授的,如果GPT 5.2被认为是展示和追求“掌声”,可能会令人失望;但如果将 GPT 5.2 视为一种追求长期稳定性并需要实际部署的工具,它超越了 OpenAI 在 GPT 5.2 中做出的一个重大产品决策:牺牲一些表达自由和创造性模型范围,以换取可预测和可靠的行为。这种不稳定是错误的。在处理具有实际下游成本的任务时,例如政策制定、规范性文件或进行认真的研究简报,这种投入是完全不可接受的。 (AI生成的图片) GPT 5.2的设计目标是保持可靠性并降低故障频率。为了实现这一目标,主要在以下三个维度进行优化: · 更严格的指令遵循:模型能够更忠实地执行用户的指令。 · 减少长时间对话中的脱轨:即使对话很长,模型也能保持话题不偏离正轨。 · 在多步骤任务中保持约束:即使任务进行了几十个步骤,它也能记住用户在步骤 1 中设置的规则。(AI 生成的图像)在一次密集的专业测试中,研究人员加载了 8,100 行原始研究数据,并设置了绝对的“绊线”规则:如果用户应该只将输出“黄色”。 GPT 5.1 在大约 47 分钟后终于打破了规则,而 GPT 5.2 rem经过 62 分钟的持续语义归纳和上下文压力后,测试人员一直处于顺从状态,直到测试人员主动停止。这证明 GPT 5.2 非常有能力在复杂的非线性对话中遵循规则。平衡动态推理和成本效率 GPT 5.2 采用“动态调整推理深度”的方法。简单提示用户先走“快捷路径”;当不确定性超过一定限度时,就会启动更慢、更深入的推理。此方法提供了最快且最便宜的回答问题的方法。虽然 GPT 5.2 的单位代币成本比 5.1 高出 1.4 倍,每百万代币的输入成本为 1.75 美元,每百万代币的输出成本为 14 美元,但得益于学习蒸馏、缓存常用文本效率片段、缓存常用效率片段和效率片段等前沿模型的最佳实践,任务成本降低了。例如GPT-5.2 Pro约390吨与去年的预览版本相比,ARC-AGI-1 任务的表现更好。减少幻觉:宁愿说“我不知道” GPT 5.2 施加了更高的惩罚机制,以防止在更大范围内引用、谎报工具的使用情况或制造未知事实。这意味着新模型更有可能承认“我不知道”,或者要求用户提供更多来源或搜索权限。这种看似“冷酷”或“保守”的行为无疑是依赖其准确性的专业用户的信任基础。 (图片由AI生成) 3.专业领域的终极对决:数据分析、PPT和编码 YouTube名人博主Eliot Prince对三种主要模型进行了深入的对比评估。他把GPT 5.2、Claude Opus 4.5和Google Gemini这三个主要模型用来测试复杂的专业任务,包括SEO策略的制定(搜索引擎优化)、PPT开发和编码。 1. SEO策略和数据分析是:Claude的“One Hit Win”测试人员上传了数千行关键词数据,并要求模型制定完整的SEO主题权威策略和主题图。 · Claude Opus 4.5:表现最佳、速度最快、“一击制胜者”。它使用 Claude Skills 自动应用品牌设置,创建带有品牌徽标、mga 品牌颜色(紫色和柠檬绿)的专业表格,包括内容分段、搜索意图、推荐页面类型和优先级信息。 · ChatGPT 5.2:思考这个问题大约 15 分钟。最初的输出相当混乱,需要第二次测试和模板(另一个电子表格)来输出按内容主题分类的可用关键字簇,其中可以包括搜索量和关键字难度等专业数据。这表明 GPT 5.2 是完全可启动的,但不像 Opus 最初那样自主。 · Google Gemini:效率低且难以利用。它只是输出一个“弱”小文件。即使测试人员问了很多问题mes,它只提供CSV文本信息或Python代码,需要用户手动复制粘贴并进行文本列处理,效率低下,并且有很多错误rap经验。 (图像由AI生成,插图不代表实际效果) 总结:在需要品牌推广和一站式交付复杂数据分析结果的任务中,Claude Opus 4.5是毫无疑问的赢家。 2. PPT生成:GPT 5.2“史诗级”图表。为了满足客户对视觉策略的需求,测试人员需要三个模型分别开发PPT。 · ChatGPT 5.2:我花了14分钟才弄清楚这一点,但结果可以用“史诗般”来形容。虽然设计相当令人愉悦,但它成功生成了动态动画图表,可以快速显示流量机会并提供 30 至 45 天内可交付成果的详细路线图。 · Claude Opus 4.5:很快就完成了。 PPT成功应用了审稿人的品牌颜色(森林绿和石灰绿)n) 而且布局精美。但其后续步骤的细节并不像GPT 5.2那么详细。 · Google Gemini:同样性能不佳,更喜欢输出Python脚本或纯文本。最终生成的PPT也有很多文字和很少的图表,看起来“几乎是AI生成的”,并且很难导出到Google Slides进行编辑。 (图片由AI生成,插图不代表实际效果) 总结:三个主模型在制作PPT上有些卡壳。 GPT 5.2 在图表深度和功能上稍好一些; Opus 4.5 再次以其标志性的交付能力脱颖而出。 3.编码能力:功能、速度和发布三个模型的测试人员被要求扮演高级前端工程师的角色,根据网站截图重建一个交互式的、专业设计的网页。 · ChatGPT 5.2:比两者都多花费 5 到 10 分钟。但最终功能还是稍微好一些。它不仅实现了测试人员所需的所有共享、定价和其他按钮,还构建完整的订单表格和预约表格,增加更多深度和功能,考虑更多细节。 · Claude Opus 4.5:很快完成。生成的页面支持发布生成“神器”和复制链接,使其成为实时网页或登陆页面,非常实用。设计也很棒,包括漂亮的悬停效果和货币切换功能。 · Google Gemini:第一个完成,但缺乏全屏预览和发布功能,需要调用外部HTML编辑器才能查看。交互性很差,页面区域的按钮只是占位符,无法执行任何操作。 (图片由AI生成,插图不代表实际效果) 总结:GPT 5.2虽然耗时最长,但由于其生成完整表格的深度和功能性,稍稍领先。 4.秘密战斗b创造力、视角和背景之间。在生成电子邮件主题行和打开挂钩的日常任务中,测试结果表明所有模型的表现大致相同,没有一个模型表现出巨大的创意优势。专业评论指出,GPT 5.2牺牲了一些创造力的空间来换取可靠性。因此,建议用户根据需求切换模型:对于“创意头脑风暴、绘图或情绪基调”等任务,maai 选择 GPT 5.1;对于“编辑、精简、编写事实、编写细节或编码”等任务,您应该选择 GPT 5.2。需要指出的是,虽然GPT 5.1的书写能力并不令人印象深刻,但它在分析损益报告等长期任务上表现良好,可以连续运行两个小时并提供准确而整洁的摘要。在形象生成方面,双子座出乎意料地获胜。测试人员的任务涉及视觉、分析和创意方面的融合:建立一个内部基于他上传的简历,以星球大战为主题的有趣职业信息图。 · ChatGPT 5.2:性能非常差。它在遵循内容政策方面存在问题,并且生成了低质量的图像,甚至无法正确拼写名称或文本。 · Google Gemsini(纳米香蕉):彻底碾压并获胜。它可以有效地捕获信息,生成清晰、拼写正确且设计精美的图形,甚至可以为命令添加“全息效果”。 Claude Opus 4.5:没有内置图像生成,但它试图通过编写代码来解决问题。最终成功创建了一个可发布、可交互的网络。 《星球大战编年史》中的页面信息图表映射种族,在编码方面表现出强大的灵活性。 (图片由AI生成,插图不代表实际效果)最终,双子座在纳米香蕉的支持下取得了明显的胜利。当然,OpenAI本身也强调了GPT-5.2在图推理和软件接口方面的错误率ce理解力下降了一半,说明虽然视觉能力有所提高,但图像生成仍然是一个短板。另外,在用户交互分析方面,Claude Opus 4.5的上下文窗口处理能力更加出色。随着对话的继续,Opus 4.5 开始压缩旧的对话内容,使其可用时间更长,从而使用户免去必须重新开始新聊天的烦恼。此外,Opus 4.5培训还包括一份名为“灵魂文档”的内部文件,该文件明确了Anthropic的使命——开发安全、有用且易于理解的AI,并警惕主动的言语攻击,解释了为什么Opus在安全性和合规性方面表现良好。 5、总结:模型定位与用户选择 GPT 5.2的发布,标志着AI巨头之间的竞争已经从追求“最高基准分数”转向追求“实用的产品策略”信任、安全、速度和成本”。模型进步变得更加专业。(AI生成的图片) · GPT 5.2可以说是可靠的主力,具有良好的屏障保持性和更严格的指令合规性。适合内容编辑、规范起草、审阅长文和深度函数式编程等任务。 · Claude Opus 4.5是品牌和数据的大师。它速度快,拥有高度优化的上下文窗口,一击必胜。更适合复杂数据分析、创意草稿、需要品牌输出的任务,Google Gemini 在图像和信息图开发、PDF 数据捕获等任务上更胜一筹,但专业任务的交付质量较低。(AI 生成的图像)那么,答案很简单:如果你需要一个严格的“执行者”,请毫不犹豫地拥抱它;如果你需要一个聪明的“创造者”,请回去看看。对于克劳德. OpenAI 并没有输,只是改变了轨道。作为用户,我们是时候摆脱“只是观看”的心态,开始思考如何充分利用这些专业的“数字员工”了。 