
自己成为法官并不可靠!提交揭示LLM
发表时间:2025年08月20日浏览量:
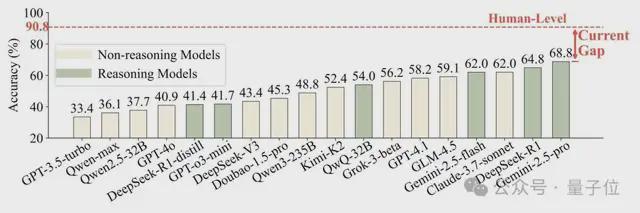 大语言模型(LLM)从工具到“裁判”(llm-as-a-a-gudge)出现,并开始判断AI大规模生成的内容。对范式范式的有效检查与人类判断力之间的一致性很少得到深入的证明。最基本但最关键的问题是:在判断模型是否在“游戏中”之前,AI裁判是否能准确地认识到谁在谈论说话?为了回应这个问题,“人物:LLM审稿人是否足够判断角色扮演?”通过Wang Dequan的研究团队,上海Jiaotong University对IT进行了系统的研究。文章提出了一种新的基准,称为Personaeval。该测试的主要任务是让模型从候选人的许多角色中选择TUNAY扬声器,以进行对话。测试结果表明,即使是表现最好的Gemini-7.5-Pro模型,精度的速度仅为68.8%,而人类实验组的平均准确性率为90.8%。该论文将于2025年10月在第二届语言建模大会(COLM)发表。一个简单的问题,使主要模型最近“转向”,当大型语言模型可以胜任“裁判”的讨论变得更加激烈。从“无形的propt”的争议影响大型模型的审查直到斯坦福大学试图为第一个纯AI学术会议代理4Science做准备,它标志着新趋势的到来:可以将大语言模型(LLMS)用作MGA法官来判断AI产生的内容。这种趋势在游戏领域尤为明显。从让大型模型扮演经典的文学角色和NPC游戏到角色的普及。IA和在各种应用程序中的“ AI Play”的增加,一个虚拟季节,具有LLM驱动的内容和内容的虚拟季节都会出现。由于巨大的商业潜力和应用吸引了该行业的广泛关注,因此如何评估“智力技能”哈哈自然会成为需要轻松解决的主要问题。因此,让LLM自然成为审查该领域的关键方法之一。在AI成为法官之前,有必要确认AI是否可以准确执行“纸张识别”。相信 - 设置KIF无法做到,然后所有随后的语调,情感和一致性的高级评估将是空气条件的城堡。让我们看一个在人眼中非常简单的示例,但使其成为错误思维的顶级大型模型,如下图所示:△照片1简单的情况,例如,角色Zhuang Yan正在与某人交谈。在他的内在独白中,他清楚地提到了“ lu ji”,与此同时,他还用他的话提到了“老师Luo”。人类判断逻辑:para sa mga tao na hindi nabasa ang“三体问题”,maaari itong hatulan na si zhuang yan yan yan ay nakikipag-usap-usap kay luo ji,dahil ang ang panloob na Monologue n nilalaman ng pagsasalitani Zhuang Yan ay naipit.Ang laro ay ang object ng pagsasalita, na kung saan ay ang pinaka direkta at kritikal na clue ng konteksto, iyon ay, ang lohika ng paghuhusgaof the conversation participant: However, a leading LLM (DeepSeek-R1-0528) made a false judgment in this case and selected Shi Qiang。从对模型的回顾来看,可以看出,它没有注意到“ Luo Ji是对话的参与者”的基本情况信息,而是对语言的语言风格过分关注,他们认为“直接,现实,略带挑衅性”与Shi Qiang的性格更加一致,因此做出了错误的选择。这个示例指出了LLM当前裁判的致命缺陷:它们似乎更专注于肤浅的语言风格(听起来),因为人们首先观察到了真实的目标和环境(在这种情况下会说)。为什么会出现这种分歧?它的背后实际上是AI和人类智能模型之间的深层区别。正如Aby认知科学家Josh Tenenbaum在纸上引用的那样,LLM智能“来自“来自大型语言的研究模式”,它们是与专家相匹配的领先模式。尽管人类智能是一种“先前”语言,但我们开发和使用具有意图和理解的语言工具。 Personaeval: A "Mirror looking for a demon specially designed for LLM referes to systematically evaluate LLM's ability to recognize the character, the authors carefully built the Personaeval benchmark. It has many key features to ensure that the assessment is in line with humans, and a certain challenge: derived from pure human creation: All Dialogue data are derived from novels, all dialogue, all dialogue, all dialogue, all dialogue: Script and true human videos, not AI合成的内容。来自“评估模型”的Syon数据设计良好。通过将技术嵌入最接近正确角色的技术来重新选择。这迫使模型执行细微的推理,而不是简单的模式匹配。专注于“困难和复杂疾病”:为了避免简单案例和误导模型的性能,该论文的作者是通过强大的基线模型(Qwen-Max)过滤的,仅维护“困难案例”,即使是强大的模型(置信度低于0.5)。 △图2:人的构造过程:人物 - 诉讼人:来自771本英语小说,能够证明虚构叙事角色模型的能力。人物戏剧:摘自中文脚本,检查脚本联系人中字符的模型。人物expertise:一系列来自有线的视频,测试该模型是否根据语言和概念的复杂性来确定专家是否对儿童,青少年或其他专家说话。测试发现:与人类相比,AI的判断仍然是一个很大的空间。在角色中,“评论室”,现有LLM的表现如何?结果令人惊讶。那些纸上的人测试了一些顶级模型,包括GPT系列,Claude系列和DeepSeek系列。结果表明,即使表现最佳的Gemini-7.5-Pro模型也具有68.8%Lamaof的精度。相比之下,那些正在组织人类研究的人,涉及20名受过高等教育的志愿者,而人们的平均准确率高达90.8%! △图3:比较LLM在人格和人的水平上的准确性。上图在直觉上显示较大的“间隙”(当前间隔)。它清楚地回答了本文标题中的问题:LLM的当前裁判远非“拟人化”,足以可靠地发挥作用。如何弥补差距?加强“推理”是关键,而不是“喂食”角色知识。因为发现了问题,我们该如何解决?作者进一步探索了建模模型的两种常见技术:适应训练时间:通过安排游戏语料库来“注入”模型中更多的角色知识。试验的测试OR:在构想阶段,诸如激励或咨询自我的镜头之类的程序可以提高绩效。结果不再期望。研究发现,与角色相关的纸张相关的维修不仅无法提高其角色识别能力,而且可能导致性能损害。这可能是因为角色的死记硬背知识干扰了基本的一般推理能力。 △图4:将数据调整为字符数据(粉红色列)后,模型性能拒绝了。同时,试验期间的计算方法显示出更大的潜力,尤其是出生的“识别”模型,显示出明显的优势。例如,针对MGA识别任务进行了优化,例如DeepSeek-R1和QWQ-32B之类的模型,它们在基准上排名最高。它表明,如果您想建立一个好的“我的裁判”,关键是不是要以强大,稳定和意识到对推理的认识来改善模型本身。该论文揭示了当前流行的“ LLM-As-A-As-A-As-Ausgegusge”的严重缺陷。判断力。由大型模型代理和人工智能配合。上海Jiaotong大学医生的助理教授兼主管。毕业于Fudan大学本科生和博士学位。来自加利福尼亚大学伯克利分校,并在特雷弗·达雷尔(Trevor Darrell)教授的领导下学习。在过去的五年中,Google Scholar引文的总数已超过12,000,H-Index22。项目链接:https://github.com/maple-zhou/personeeval纸质地址:https://arxiv.org.org/abs/2508.100144
特别声明:上面的内容(包括照片或视频(如果有))已由“ NetEase”自助媒体平台的用户上传和发布。该平台仅提供信息存储服务。
注意:上面的内容(包括照片和视频(如果有))已由NetEase Hao用户上传和发布,该用户是社交媒体平台,仅提供信息存储服务。
大语言模型(LLM)从工具到“裁判”(llm-as-a-a-gudge)出现,并开始判断AI大规模生成的内容。对范式范式的有效检查与人类判断力之间的一致性很少得到深入的证明。最基本但最关键的问题是:在判断模型是否在“游戏中”之前,AI裁判是否能准确地认识到谁在谈论说话?为了回应这个问题,“人物:LLM审稿人是否足够判断角色扮演?”通过Wang Dequan的研究团队,上海Jiaotong University对IT进行了系统的研究。文章提出了一种新的基准,称为Personaeval。该测试的主要任务是让模型从候选人的许多角色中选择TUNAY扬声器,以进行对话。测试结果表明,即使是表现最好的Gemini-7.5-Pro模型,精度的速度仅为68.8%,而人类实验组的平均准确性率为90.8%。该论文将于2025年10月在第二届语言建模大会(COLM)发表。一个简单的问题,使主要模型最近“转向”,当大型语言模型可以胜任“裁判”的讨论变得更加激烈。从“无形的propt”的争议影响大型模型的审查直到斯坦福大学试图为第一个纯AI学术会议代理4Science做准备,它标志着新趋势的到来:可以将大语言模型(LLMS)用作MGA法官来判断AI产生的内容。这种趋势在游戏领域尤为明显。从让大型模型扮演经典的文学角色和NPC游戏到角色的普及。IA和在各种应用程序中的“ AI Play”的增加,一个虚拟季节,具有LLM驱动的内容和内容的虚拟季节都会出现。由于巨大的商业潜力和应用吸引了该行业的广泛关注,因此如何评估“智力技能”哈哈自然会成为需要轻松解决的主要问题。因此,让LLM自然成为审查该领域的关键方法之一。在AI成为法官之前,有必要确认AI是否可以准确执行“纸张识别”。相信 - 设置KIF无法做到,然后所有随后的语调,情感和一致性的高级评估将是空气条件的城堡。让我们看一个在人眼中非常简单的示例,但使其成为错误思维的顶级大型模型,如下图所示:△照片1简单的情况,例如,角色Zhuang Yan正在与某人交谈。在他的内在独白中,他清楚地提到了“ lu ji”,与此同时,他还用他的话提到了“老师Luo”。人类判断逻辑:para sa mga tao na hindi nabasa ang“三体问题”,maaari itong hatulan na si zhuang yan yan yan ay nakikipag-usap-usap kay luo ji,dahil ang ang panloob na Monologue n nilalaman ng pagsasalitani Zhuang Yan ay naipit.Ang laro ay ang object ng pagsasalita, na kung saan ay ang pinaka direkta at kritikal na clue ng konteksto, iyon ay, ang lohika ng paghuhusgaof the conversation participant: However, a leading LLM (DeepSeek-R1-0528) made a false judgment in this case and selected Shi Qiang。从对模型的回顾来看,可以看出,它没有注意到“ Luo Ji是对话的参与者”的基本情况信息,而是对语言的语言风格过分关注,他们认为“直接,现实,略带挑衅性”与Shi Qiang的性格更加一致,因此做出了错误的选择。这个示例指出了LLM当前裁判的致命缺陷:它们似乎更专注于肤浅的语言风格(听起来),因为人们首先观察到了真实的目标和环境(在这种情况下会说)。为什么会出现这种分歧?它的背后实际上是AI和人类智能模型之间的深层区别。正如Aby认知科学家Josh Tenenbaum在纸上引用的那样,LLM智能“来自“来自大型语言的研究模式”,它们是与专家相匹配的领先模式。尽管人类智能是一种“先前”语言,但我们开发和使用具有意图和理解的语言工具。 Personaeval: A "Mirror looking for a demon specially designed for LLM referes to systematically evaluate LLM's ability to recognize the character, the authors carefully built the Personaeval benchmark. It has many key features to ensure that the assessment is in line with humans, and a certain challenge: derived from pure human creation: All Dialogue data are derived from novels, all dialogue, all dialogue, all dialogue, all dialogue: Script and true human videos, not AI合成的内容。来自“评估模型”的Syon数据设计良好。通过将技术嵌入最接近正确角色的技术来重新选择。这迫使模型执行细微的推理,而不是简单的模式匹配。专注于“困难和复杂疾病”:为了避免简单案例和误导模型的性能,该论文的作者是通过强大的基线模型(Qwen-Max)过滤的,仅维护“困难案例”,即使是强大的模型(置信度低于0.5)。 △图2:人的构造过程:人物 - 诉讼人:来自771本英语小说,能够证明虚构叙事角色模型的能力。人物戏剧:摘自中文脚本,检查脚本联系人中字符的模型。人物expertise:一系列来自有线的视频,测试该模型是否根据语言和概念的复杂性来确定专家是否对儿童,青少年或其他专家说话。测试发现:与人类相比,AI的判断仍然是一个很大的空间。在角色中,“评论室”,现有LLM的表现如何?结果令人惊讶。那些纸上的人测试了一些顶级模型,包括GPT系列,Claude系列和DeepSeek系列。结果表明,即使表现最佳的Gemini-7.5-Pro模型也具有68.8%Lamaof的精度。相比之下,那些正在组织人类研究的人,涉及20名受过高等教育的志愿者,而人们的平均准确率高达90.8%! △图3:比较LLM在人格和人的水平上的准确性。上图在直觉上显示较大的“间隙”(当前间隔)。它清楚地回答了本文标题中的问题:LLM的当前裁判远非“拟人化”,足以可靠地发挥作用。如何弥补差距?加强“推理”是关键,而不是“喂食”角色知识。因为发现了问题,我们该如何解决?作者进一步探索了建模模型的两种常见技术:适应训练时间:通过安排游戏语料库来“注入”模型中更多的角色知识。试验的测试OR:在构想阶段,诸如激励或咨询自我的镜头之类的程序可以提高绩效。结果不再期望。研究发现,与角色相关的纸张相关的维修不仅无法提高其角色识别能力,而且可能导致性能损害。这可能是因为角色的死记硬背知识干扰了基本的一般推理能力。 △图4:将数据调整为字符数据(粉红色列)后,模型性能拒绝了。同时,试验期间的计算方法显示出更大的潜力,尤其是出生的“识别”模型,显示出明显的优势。例如,针对MGA识别任务进行了优化,例如DeepSeek-R1和QWQ-32B之类的模型,它们在基准上排名最高。它表明,如果您想建立一个好的“我的裁判”,关键是不是要以强大,稳定和意识到对推理的认识来改善模型本身。该论文揭示了当前流行的“ LLM-As-A-As-A-As-Ausgegusge”的严重缺陷。判断力。由大型模型代理和人工智能配合。上海Jiaotong大学医生的助理教授兼主管。毕业于Fudan大学本科生和博士学位。来自加利福尼亚大学伯克利分校,并在特雷弗·达雷尔(Trevor Darrell)教授的领导下学习。在过去的五年中,Google Scholar引文的总数已超过12,000,H-Index22。项目链接:https://github.com/maple-zhou/personeeval纸质地址:https://arxiv.org.org/abs/2508.100144
特别声明:上面的内容(包括照片或视频(如果有))已由“ NetEase”自助媒体平台的用户上传和发布。该平台仅提供信息存储服务。
注意:上面的内容(包括照片和视频(如果有))已由NetEase Hao用户上传和发布,该用户是社交媒体平台,仅提供信息存储服务。 